Python 用字典写 NFA to DFA
17 March 2013
NFA to DFA python
比如说这个字典:
这是我的输入,输入一个NFA
dictNFA = {
'q1': { 'e': ['q2', 'q11'], '0': [''], '1': [''], 'acep': False, 'start': True },
'q2': { 'e': ['q3', 'q5'], '0': [''], '1': [''], 'acep': False, 'start': False },
'q3': { 'e': [''], '0': [''], '1': ['q4'], 'acep': False, 'start': False },
'q4': { 'e': ['q5', 'q3'], '0': [''], '1': [''], 'acep': False, 'start': False },
'q5': { 'e': [''], '0': ['q6'], '1': [''], 'acep': False, 'start': False },
'q6': { 'e': ['q7', 'q9'], '0': [''], '1': [''], 'acep': False, 'start': False },
'q7': { 'e': [''], '0': [''], '1': ['q8'], 'acep': False, 'start': False },
'q8': { 'e': ['q9', 'q7'], '0': [''], '1': [''], 'acep': False, 'start': False },
'q9': { 'e': [''], '0': ['q10'], '1': [''], 'acep': False, 'start': False },
'q10': { 'e': ['q11', 'q2'], '0': [''], '1': [''], 'acep': False, 'start': False },
'q11': { 'e': ['q12', 'q14'], '0': [''], '1': [''], 'acep': False, 'start': False },
'q12': { 'e': [''], '0': [''], '1': ['q13'], 'acep': False, 'start': False },
'q13': { 'e': ['q14', 'q12'], '0': [''], '1': [''], 'acep': False, 'start': False },
'q14': { 'e': [''], '0': [''], '1': [''], 'acep': True, 'start': False },
}
dictDFA.keys()输出的是列表:
['q14', 'q11', 'q10', 'q13', 'q12', 'q1', 'q3', 'q2', 'q5', 'q4', 'q7', 'q6', 'q9', 'q8']
顺序是固定的这个形式
def loopB(xNFA, xe, tmpInI):
当xe=ε时这个是用循环将q1->q2(消耗ε:the empty string)q1->q11
然后q2->q3...
当xe=0时这个循环q5->q6(消耗0)
当xe=1时这个循环q7->q8(消耗1)
如果要找q1, 不能用dictDFA.keys()[0]
从这个列表得知dictDFA.keys()[0]变成了'q14'
q1的关键是它的'start'是true
那么只能用循环一个一个找
def seachStartOrAccept(startOrAccept): #这个是用来查账它开始start或者结束accept(accept就是两个圈)
for x in xrange(0, len(dictNFA.keys())):
if dictNFA.values()[x][startOrAccept]:
return dictNFA.keys()[x]
dictNFA.values()[x][startOrAccept]其实是dictNFA.values()[x]['start']
tmpII = list(set(tmpII))用这个函数是为了除掉列表里面的重复项,列表重复是允许的,字典里面重复是不允许的。
dictDFA.update({ str(tmpIII): { '0': tmpIIIa, '1': tmpIIIb, 'start': False, 'acep': False } })
字典用update()添加新项目,如果重复,那么新添加的项会替换旧的项
程序开始:
先得出第一个项tmp0
然后tmp0消耗0得到tmp1
tmp0消耗1得到tmp2
tmp1消耗0得到tmp3
tmp1消耗1得到tmp4
。。。以此类推。。。
可以得到形如:
0 1 2
1 3 4
2 5 6
3 7 8
...
树状图如下:
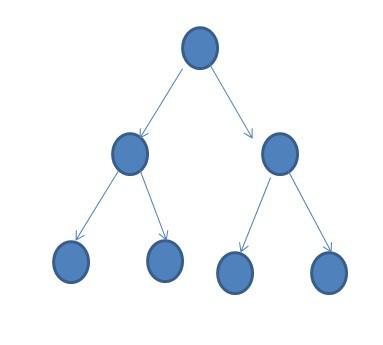
用一个循环让它循环下去,什么时候停止呢?
就是当我被选出来的数,比如说4和之前的1相同,那么4就停止了
if str(tmpIIIa) not in dictDFA.keys():
loopNFAtoDFA(tmpIIIa)
最后得到这个结构的字典:
dictDFAend = {
str(qA): { '0': 0, '1': 1, 'start': False, 'acep': False },
str(qB): { '0': 0, '1': 1, 'start': False, 'acep': False },
str(qC): { '0': 0, '1': 1, 'start': False, 'acep': False },
str(qD): { '0': 0, '1': 1, 'start': False, 'acep': False },
str(qE): { '0': 0, '1': 1, 'start': False, 'acep': False },
}
NFA to DFA 原理如此图
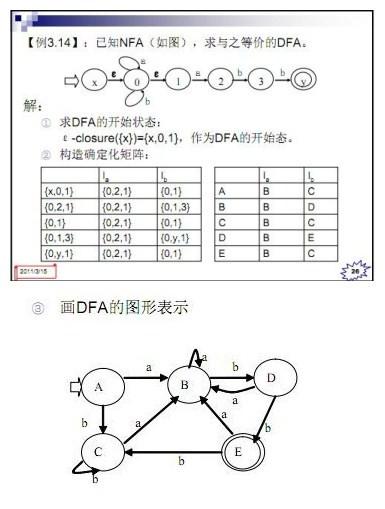
接下来最小化这个DFA:
首先将non-accept组成一组,accept组成一组
non-accept消耗0归不同类的各自分开,若为同一类,则在一起。
non-accept一类的消耗1归不同类的各自分开,若为同一类,则在一起。
最后连接每一个类。
NFA转化为DFA,并且Minimum DFA过程如下:
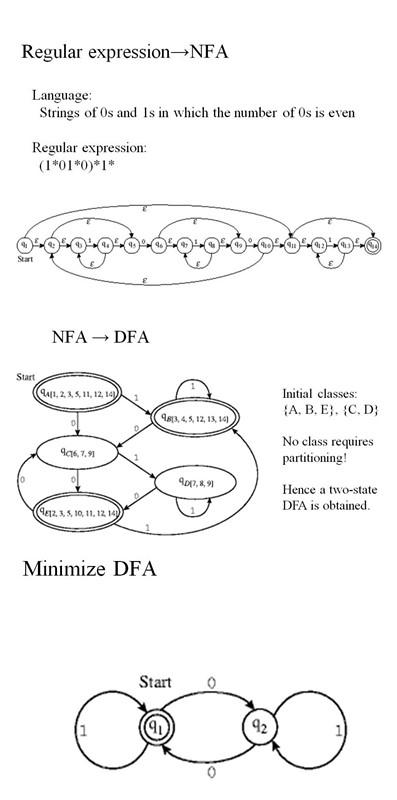
blog comments powered by Disqus